Redirects are fundamental components of website management, acting as signposts on the digital highway. They guide both users and search engine crawlers from one URL to another, ensuring traffic reaches the intended destination even when the original path has changed. Far from being mere technical footnotes, redirects are strategic tools vital for maintaining a healthy online presence.
Their importance stems from a dual role. Firstly, they are critical for user experience. When a user clicks a link or bookmark expecting certain content, encountering a "404 Not Found" error is frustrating and often leads them to abandon the site. Well-implemented redirects ensure seamless navigation, automatically forwarding users from old or non-existent URLs to relevant, live pages, thus preserving user satisfaction and trust.
Secondly, redirects are indispensable for search engine optimisation (SEO). Search engines invest significant effort in crawling and indexing the web; redirects inform them when content has moved permanently or temporarily. Proper redirection helps preserve the hard-earned ranking signals, often referred to as "link equity" or "PageRank," associated with the original URL, transferring much of this value to the new destination. This prevents catastrophic drops in search visibility when URLs inevitably change due to site restructuring, content updates, or migrations. Furthermore, efficient redirect management helps search engines crawl a site more effectively, preventing wasted resources on dead ends.
Ignoring or mismanaging redirects can have severe consequences. Broken links lead to poor user experiences, increased bounce rates, and potentially lost conversions. From an SEO perspective, failing to redirect properly can result in the loss of valuable link equity, fractured ranking signals, wasted crawl budget as search engines repeatedly hit non-existent pages, and ultimately, diminished organic traffic and damaged site credibility.
Understanding how redirects function and how to implement them correctly is therefore not optional, but essential for anyone managing a website. This guide provides a comprehensive overview of different redirect types, their specific impacts on SEO, common pitfalls to avoid, and best practices for implementation and monitoring, ensuring your website navigates changes effectively while safeguarding its search performance. The communication between a website owner, its users, and search engines relies heavily on these signals; miscommunication, such as using the wrong redirect type or creating confusing pathways like loops, directly translates to negative outcomes for both user experience and SEO effectiveness. The need for meticulous redirect management grows significantly with website size and complexity; larger sites undergoing frequent updates, migrations, or structural changes face amplified risks from inefficient redirection, making careful planning and execution paramount.
Decoding Redirect Types: Choosing Your Path
At the heart of redirection lies the HTTP status code, specifically those in the 3xx series. These codes are server-side responses that instruct the browser or search engine crawler on how to proceed when the requested URL is not the final destination. Understanding the nuances between the primary redirect types is crucial for effective SEO.
301 Moved Permanently:Often hailed as the "gold standard" for SEO , the 301 status code signals that a URL has permanently moved to a new location. It tells search engines and browsers that the old URL is defunct and should no longer be requested or indexed; the new URL is the definitive replacement. Its primary SEO benefit is its ability to pass the majority of link equity (ranking power) from the old URL to the new one, typically estimated between 90-99%. This makes it essential for scenarios like changing domain names, migrating to HTTPS, rebranding involving URL changes, permanently deleting pages while providing a relevant alternative, or consolidating duplicate content into a single canonical version. It's worth noting that browsers may cache 301 responses aggressively, meaning users might be automatically sent to the new URL on subsequent visits without re-checking the old one.
302 Found / Moved Temporarily:The 302 status code indicates that a resource has been temporarily moved. The key implication is that the original URL is expected to be reinstated at some point. Historically, 302 redirects were not considered reliable for passing link equity, as search engines understood the move was temporary. While Google representatives have stated that they may treat long-standing 302s like 301s if they appear permanent, relying on this is risky from an SEO perspective. Using a 302 for a permanent move can lead to confusion, potentially splitting ranking signals or causing the old URL to remain indexed. Legitimate use cases include A/B testing different page versions, redirecting users during very short-term site maintenance, or handling temporary promotional pages. For permanent changes, 301 is almost always the safer and clearer choice for SEO.
307 Moved Temporarily:Introduced as part of the HTTP 1.1 specification, the 307 redirect is essentially a more specific version of the 302, explicitly designated for temporary moves. Its crucial distinguishing feature is that it mandates the client (browser/bot) to preserve the original HTTP request method (e.g., GET, POST) when making the request to the new URL. This is vital for situations like temporarily redirecting a page that handles form submissions via POST; using a 302 might cause the browser to incorrectly switch to a GET request for the new URL, potentially breaking functionality. For SEO purposes, search engines generally treat 307s like 302s – as temporary signals that do not pass link equity.
308 Permanent Redirect:The 308 status code is the permanent counterpart to the 307. Like the 301, it signals that a resource has permanently moved to a new location. Its key difference from the 301 is that it also mandates the preservation of the original HTTP request method. This makes it the technically correct choice for permanently moving URLs that handle non-GET requests, such as forms processing POST data or API endpoints. Crucially for SEO, the 308 redirect passes link equity just like a 301 , and Google has confirmed they treat 308s essentially the same as 301s in terms of indexing and ranking signal transfer. While sometimes described as technically "cleaner" if request methods are mixed or unknown, for most standard web page moves (which use GET), the 301 remains perfectly sufficient and more widely understood.
The inclusion of 307 and 308 redirects reflects the web's evolution towards more complex interactions beyond simple page fetching, such as those involving APIs and dynamic form submissions. These newer codes provide necessary precision. However, the decision between 301 and 308 (or 302 and 307) primarily rests on the technical requirement of preserving the request method, not on seeking a different SEO outcome regarding permanence or link equity transfer, as Google handles the permanent types (301/308) similarly.
Link Equity and Redirects
One of the most critical functions of redirects, particularly 301 and 308, is the preservation and transfer of "link equity". Also known as PageRank, link juice, or SEO authority, link equity represents the value or ranking power passed from one page to another through hyperlinks. Pages accumulate this equity over time through internal and external links, and it's a significant factor in how search engines rank pages.
Permanent redirects (301 and 308) are specifically designed by HTTP standards and interpreted by search engines as the primary mechanism for transferring the bulk of this accumulated value when a page permanently moves. While the exact percentage transferred has been debated – with figures like 90-99% often cited and Google representatives sometimes suggesting all 30x redirects pass PageRank – the established SEO best practice is unequivocal: use 301 or 308 for permanent moves to reliably consolidate ranking signals and pass authority. The semantic clarity of "permanent" signals to search engines that the old page's value should now be attributed to the new one.
Relying on temporary redirects (302 or 307) for permanent changes introduces unnecessary risk. Because these codes signal a temporary situation, search engines may be hesitant to fully transfer link equity or may continue to index the original URL alongside the temporary one, effectively splitting the ranking signals and diluting the potential of the new page. This can significantly hinder the new page's ability to achieve the ranking position previously held by the original.
Therefore, preserving link equity is a cornerstone reason for meticulously implementing 301/308 redirects during major website changes like domain migrations, rebranding efforts that involve URL changes, switching to HTTPS, or consolidating multiple weaker pages into a single stronger one. It ensures that the authority built over potentially years is not lost but is instead channeled to the new location. While there might be a theoretical small loss of equity even through a single 301/308 hop , this is generally considered minimal compared to the potential losses from using the wrong redirect type or from issues like redirect chains, which demonstrably dilute equity with each step. The practical focus should be on using the correct permanent redirect type (301/308) for permanent moves to maximise the likelihood of proper signal transfer, rather than getting caught up in precise percentage debates.
However, simply using a 301 or 308 does not automatically guarantee perfect SEO value transfer. The implementation must be clean, avoiding issues like chains (discussed next), and critically, the destination page must be relevant to the original. Redirecting a page about "blue widgets" to a completely unrelated page about "red shoes," even with a 301, is unlikely to transfer the topical authority effectively and may confuse both users and search engines. Relevance is key for the redirect to make sense contextually and for the transferred equity to be meaningful.
Redirects and Crawl Budget: Making Every Crawl Count
Search engines like Google don't have infinite resources; they allocate a finite amount of time and resources, known as the "crawl budget," to crawling any given website. This budget determines how many pages can be crawled and how often. For large websites, sites with frequently updated content, or sites undergoing significant changes, optimizing crawl budget is crucial to ensure important pages are discovered, indexed, and updated in a timely manner.
Redirects inherently consume crawl budget because each redirect encountered forces the crawler to make an additional HTTP request to follow the path to the next URL. While a single, necessary redirect is usually not problematic, inefficiencies in redirect implementation can significantly waste this limited budget.
Redirect Chains are a major culprit. When a URL redirects to another URL, which then redirects to a third (or more), each "hop" consumes crawl budget. Googlebot typically follows a limited number of redirects in a chain (often cited as up to five hops) before abandoning the crawl attempt to conserve resources. This means that content located at the end of a long redirect chain may never be reached or indexed by the crawler. Furthermore, chains can delay the indexing of the final destination page and potentially slow down the crawling of other important content on the site if the budget is squandered on unnecessary hops.
Redirect Loops, where a chain inadvertently directs back to an earlier URL (e.g., A -> B -> C -> A), are even more detrimental. They create an infinite trap for crawlers, consuming budget endlessly until the crawler gives up, and making the intended content completely inaccessible.
Soft 404 Errors also waste crawl budget. These occur when a non-existent page incorrectly returns a 200 OK success code instead of a 404 Not Found or 410 Gone code. Google crawls the URL expecting content, receives a success code, but then has to render and analye the page to realiit's actually an error page (or thin content). This extra processing consumes crawl resources unnecessarily, and these pages may continue to be crawled repeatedly.
Client-Side Redirects (Meta Refresh and JavaScript redirects) can also be inefficient from a crawl budget perspective. Unlike server-side 3xx redirects which are signaled immediately in the HTTP header, client-side redirects require the crawler to download, parse, and render the page content to discover the redirect instruction. This rendering process consumes significantly more resources and time compared to simply reading a header, potentially slowing down the overall crawl.
Optimising crawl budget in relation to redirects involves several best practices:
Eliminate Chains and Loops: Always redirect directly from the original URL to the final destination URL. Audit regularly to find and fix chains by updating the initial redirect.
Fix Soft 404s: Ensure non-existent pages return a proper 404 or 410 status code.
Prioritise Server-Side Redirects: Use 3xx redirects whenever technically possible, as they are more efficient for crawlers than client-side methods.
Update Internal Links: Regularly audit internal links and update any that point to redirected URLs to point directly to the final destination. This saves crawlers (and users) the extra hop.
Maintain Clean Sitemaps: Ensure XML sitemaps list only the final, canonical destination URLs, not URLs that are redirected.
These inefficiencies create an "opportunity cost." Every bit of crawl budget wasted on navigating a redirect chain or processing a soft 404 is budget that could have been used to discover new content, index important updates, or crawl high-priority pages. Proactively updating internal links to bypass redirects is a prime example of efficiency; while the redirect might function, forcing the crawler through it repeatedly is wasteful. Fixing the source link directly saves resources and improves efficiency.
Example of a 301 redirect implemented due to a URL change.
Strategic Redirect Implementation: Common Scenarios
Applying the correct redirect strategy is crucial in various common website management situations. Here’s how to approach them:
Website Migrations (Domain Change/Restructuring): This is perhaps the most critical scenario for redirects. When moving a website to a new domain or significantly changing its URL structure, implementing page-to-page 301 or 308 redirects for every old URL to its corresponding new URL is essential. This painstaking process is vital to transfer the accumulated SEO value (link equity) and ensure users arriving via old links or bookmarks land on the correct new page. Careful mapping of old URLs to new ones is required before the migration. Post-migration, internal links within the content must be updated to point to the new URLs, and the XML sitemap should be updated with the new URLs only.
HTTP to HTTPS Migration: Moving a site to secure HTTPS requires site-wide 301 or 308 redirects from every HTTP URL to its identical HTTPS version. This ensures all traffic is forced to the secure version and consolidates ranking signals to the HTTPS URLs. Canonical tags should also be updated to reference the HTTPS versions. Implementing HTTP Strict Transport Security (HSTS) can further enhance security, although it can sometimes lead to browsers performing internal 307 redirects if configured.
Rebranding (with URL changes): Similar to a domain change, if a rebrand involves changing the website's domain name or URL structure, 301 or 308 redirects are necessary to transfer the existing brand authority, link equity, and user trust associated with the old URLs to the new ones. This prevents having to rebuild the site's SEO presence from scratch.
Content Pruning/Deletion: When removing pages:
If the page is truly gone and there is no relevant replacement content anywhere on the site, the URL should return a 404 (Not Found) or 410 (Gone) status code. The 410 code is a slightly stronger signal that the removal is permanent and intentional. This tells search engines to de-index the page.
If there is a relevant replacement page (e.g., an updated version, a similar product, a parent category page), then implement a 301 redirect from the old URL to the most relevant new URL. This preserves user experience and passes link equity.
Avoid indiscriminately redirecting all deleted pages to the homepage. This is poor practice, often results in soft 404 errors as the homepage is rarely relevant, and provides a bad user experience. The redirect target must be the most relevant possible alternative. If no relevant alternative exists, a 404/410 is better than an irrelevant redirect.
Content Consolidation: When merging several similar or overlapping pages into a single, comprehensive "mother" asset, use 301 redirects from each of the old, merged pages to the new canonical URL. This funnels all traffic and link equity from the retired pages into the consolidated piece, strengthening its authority and ranking potential.
URL Structure Changes/Site Restructuring: If reorganising site categories or changing URL paths for existing content, 301 or 308 redirects are needed to map the old URLs to their new locations. This ensures that internal links, external links, and user bookmarks continue to function correctly and pass SEO value.
Handling www vs. non-www and Trailing Slashes: Websites should consistently use one preferred version of their domain (e.g., https://www.example.com or https://example.com) and URL format (e.g., with or without a trailing slash). Implement 301 redirects to enforce the chosen canonical version, redirecting all other variations to it. This prevents duplicate content issues and consolidates link signals.
Across all these scenarios, the underlying goal is to manage change effectively. Redirects act as the bridge, ensuring continuity for users and search engines by clearly signaling where content has moved or why it's no longer available, thereby preserving accumulated value and preventing confusion. The choice of redirect target when dealing with removed content is particularly important; relevance must guide the decision to avoid confusing users and triggering soft 404s.
Client-Side Redirects: When and How (Cautiously)
While server-side 3xx redirects are the standard and preferred method for SEO, there are situations where redirection happens on the client-side – meaning the redirect is triggered within the user's browser after the initial page starts loading, rather than immediately by the server. The two main types are Meta Refresh and JavaScript redirects.
Meta Refresh:This method uses an HTML meta tag within the <head> section: <meta http-equiv="refresh" content="X; URL='new-url.html'">, where X is the delay in seconds before redirecting. These often display messages like "If you are not redirected in X seconds, click here".
SEO Implications: Meta refreshes are generally not recommended for SEO purposes. They are slower than server-side redirects because the browser must first download and parse the HTML to find the tag. They can be confusing for users, potentially disrupt the browser's back button functionality, and may not reliably pass link equity. While Google has indicated it might treat an instant meta refresh (0-second delay) as equivalent to a 301 , server-side redirects remain the strongly preferred and more reliable method for permanent moves.
JavaScript Redirects:These use JavaScript code, such as window.location.href = 'new-url.html', to instruct the browser to load a different URL.
SEO Implications: Similar to meta refreshes, JavaScript redirects are generally not the preferred method for SEO. The critical drawback is that search engines like Google must render the page (execute the JavaScript) to discover the redirect instruction. This rendering process consumes more crawl resources and introduces delays compared to simply reading an HTTP header. If JavaScript execution fails or is blocked, the redirect may be missed entirely. Furthermore, not all search engine crawlers execute JavaScript effectively, meaning the redirect might be invisible to them. Poor implementation can lead to indexing the intermediate page or even soft 404 errors.
When Might Client-Side Redirects Be Used?Despite the drawbacks, there are niche scenarios:
As a last resort when server-side configuration is impossible due to lack of access or platform limitations.
Sometimes used after user interactions like form submissions or logins, where the immediate SEO impact of the redirect itself is less critical.
A specific valid use case exists for Single Page Applications (SPAs). To avoid soft 404 errors when a non-existent route is accessed within a client-rendered SPA, JavaScript can be used to redirect the user to a dedicated error URL (e.g., /not-found) where the server is configured to return a proper 404 status code. In this context, the JS redirect facilitates the correct server response.
Best Practices (If Unavoidable):
For Meta Refresh: If attempting to signal permanence, use a 0-second delay, but strongly consider if a server-side redirect is truly impossible.
For JavaScript Redirects: Place the redirect script as high as possible in the HTML <head> to minimie the delay before execution. Ensure the page triggering the redirect is not indexable itself (e.g., via noindex tag) if it contains no meaningful content. Crucially, ensure the JavaScript is accessible and renderable by Googlebot.
The fundamental issue with client-side redirects for SEO is their reliance on the rendering process. This inherent inefficiency and potential for failure make server-side 3xx redirects the far superior choice whenever control over server configuration is available.
Navigating the Pitfalls: Chains, Loops, and Soft 404s
Even with an understanding of redirect types, implementation errors can severely undermine SEO efforts. Three common pitfalls require particular attention: redirect chains, redirect loops, and soft 404 errors.
Redirect Chains: A redirect chain occurs when a requested URL redirects to a second URL, which then redirects to a third, and potentially more, before reaching the final destination (e.g., URL A -> URL B -> URL C).
Impact: Chains are detrimental for several reasons. They significantly waste crawl budget, as search engine bots must make multiple requests to follow the path. Googlebot may abandon the chain after a certain number of hops (usually around 5), meaning the final destination might not be crawled or indexed. Each hop can also potentially dilute link equity being passed, weakening the final page's authority. Finally, they increase page load time for users, creating a poor experience.
Causes: Chains often arise accidentally during website migrations or sequential content updates where previous redirects are not audited and updated to point to the latest final destination. This lack of proper change management leads to layered, inefficient redirect paths.
Fix: Identify chains using website crawlers (like Screaming Frog, Oncrawl), browser developer tools, or server log analysis. The solution is to update the very first redirect in the chain to point directly to the final destination URL, eliminating all intermediate steps.
Example of a short redirect chain --> there's more then 1 redirect until the final destination is reached.
Redirect Loops:A redirect loop is a specific type of chain where the sequence eventually redirects back to a URL earlier in the chain, creating an infinite cycle (e.g., URL A -> URL B -> URL A).
Impact: Loops make the content completely inaccessible to both users (who will see a browser error like "ERR_TOO_MANY_REDIRECTS") and search engine crawlers (which get trapped and eventually abandon the attempt). They are a severe waste of crawl budget and prevent the involved pages from being indexed.
Fix: Identify loops using website crawler tools. Analyze the loop to pinpoint the incorrect redirect step. Break the loop by correcting the faulty redirect to point to the intended final destination or by removing the redirect entirely if it's no longer needed.
Soft 404 Errors:A soft 404 occurs when a URL for a page that doesn't actually exist (or has very thin, unhelpful content) returns a 200 OK (Success) HTTP status code instead of the appropriate 404 (Not Found) or 410 (Gone) code.
Common Causes: Serving a custom "Page Not Found" design but failing to send the 404 header; redirecting all non-existent URLs to the homepage; having empty product category pages or internal search result pages that return 200 OK; pages with extremely thin or boilerplate content that Google deems unhelpful.
Impact: Soft 404s confuse search engines, making it harder for them to understand the site's structure. They waste crawl budget as Google crawls these URLs expecting valid content, only to find an error or useless page served with the wrong status code. This can ultimately lead to these URLs (and potentially others, if budget is wasted) not being properly indexed or being removed from the index.
Fix: The fix depends on the nature of the URL:
If the page truly should not exist: Configure the server to return a proper 404 or 410 status code directly for that URL. A custom, helpful 404 page can still be displayed to the user, but it must be served with the 404 HTTP header. Do not redirect 404s to the homepage. This practice ignores the principle of relevance; the homepage is rarely a suitable substitute for the specific content the user or bot sought, leading to confusion and the soft 404 signal.
If the page content has moved: Implement a 301 or 308 redirect to the new, relevant URL.
If the page exists but has thin content: Significantly improve the content to provide genuine value.
If the page exists but should not be indexed (e.g., empty search results): Use a noindex meta tag on the page or potentially block via robots.txt if appropriate (though noindex allows crawling while preventing indexing, which can be preferable).
How to Spot Redirect Issues
Want to make sure your redirects are working properly? Check here:
Google Search Console → Look for 404s and redirected URLs.
Google Analytics → Find error pages that still get traffic.
SEO tools (like Screaming Frog) → Identify redirect chains, missing redirects, or bad targets.
Auditing and Monitoring: Keeping Your Redirects Healthy
Redirect management is not a "set it and forget it" task. Websites evolve, content changes, and platforms get updated, all of which can introduce redirect errors or render existing redirects obsolete or inefficient. Therefore, regular auditing and ongoing monitoring are essential to maintain a healthy redirect structure.
Tools for Identification:A combination of tools provides the most comprehensive view:
Google Search Console (GSC): This free tool from Google is indispensable. The Index Coverage report highlights pages with redirect errors, confirms which redirected pages Google has processed ("Page with redirect" status), and flags soft 404 errors. The URL Inspection Tool allows checking the status and redirect path of individual URLs as Google sees them.
Website Crawlers: Desktop software (like Screaming Frog SEO Spider, Sitebulb) or cloud platforms (like Oncrawl, Deepcrawl) are crucial for proactively identifying issues across the entire site. Configure them to follow redirects and report on status codes, redirect chains, loops, and target URLs.
Browser Developer Tools: The "Network" tab in Chrome DevTools or similar browser tools allows manual inspection of the HTTP headers and redirect sequence for any single URL visited.
Server Log Analysis: Analysing server access logs can reveal how search engine bots (and users) are actually interacting with redirects, identifying frequently hit redirected URLs, crawl traps, or unexpected status codes.
Regular Audit Process:Implementing a routine audit process helps catch issues early:
Schedule Periodic Crawls: Depending on site size and the frequency of changes, run full site crawls specifically configured to detect redirect issues (chains, loops, incorrect types like 302s for permanent moves, redirects leading to 404s) on a regular basis (e.g., monthly, quarterly).
Monitor GSC: Check the Coverage report in GSC frequently (e.g., weekly) for any newly reported errors or warnings related to redirects or indexing.
Check Internal Links: During audits, identify internal links that point to URLs which then redirect. Update these source links to point directly to the final destination URL to improve efficiency.
Post-Change Verification: Always perform a thorough redirect check immediately after major website changes, such as migrations, platform updates, redesigns, or significant content restructuring.
Sitemap Hygiene: Regularly verify that your XML sitemap(s) contain only live, final destination URLs (status code 200) and do not include any URLs that redirect.
Proactive monitoring allows for the early detection and correction of redirect problems before they escalate and cause significant harm to crawl budget allocation, link equity flow, or user experience. Waiting for ranking drops or user complaints is a reactive approach that indicates damage has already occurred. Combining insights from different tools offers a more robust picture: GSC shows Google's view, crawlers simulate discovery site-wide, and logs reveal actual bot behavior, enabling better prioritization of fixes.
Conclusion: Mastering Redirects for a Healthier Site
Redirects are far more than a technical necessity; they are a critical element of effective technical SEO and website management. Properly implemented, they ensure seamless user journeys, preserve hard-won search engine rankings, and allow websites to evolve without losing valuable authority or confusing search crawlers.
The key takeaways are clear:
Choose the Right Signal: Understand the difference between permanent (301, 308) and temporary (302, 307) redirects and use the appropriate code for the situation. Consider whether the request method needs preservation (using 307/308) for non-standard requests.
Prioritize Server-Side: Whenever possible, use server-side 3xx redirects, as they are more efficient and reliable for SEO than client-side methods like Meta Refresh or JavaScript redirects.
Preserve Link Equity: Leverage 301 and 308 redirects for permanent moves to transfer the maximum possible ranking power to new URLs.
Maintain Cleanliness and Relevance: Avoid redirect chains and loops at all costs, as they waste crawl budget and harm user experience. Ensure redirect targets are relevant to the original URL, and fix soft 404 errors by serving correct status codes (404/410 for gone pages, 200 for valid pages, 301/308 for moved pages).
Audit Continuously: Redirect management is an ongoing process. Regularly use tools like Google Search Console and website crawlers to monitor for errors and inefficiencies.
Ultimately, effective redirect management is about managing change and maintaining clarity. As websites grow and adapt, redirects serve as the essential communication tool that ensures these changes don't result in broken pathways, lost SEO value, or confusion for users and search engines. Mastering redirects is mastering a fundamental aspect of technical SEO, providing the stable foundation upon which other efforts like content creation, link building, and user experience optimiion can thrive. By implementing redirects thoughtfully and monitoring them diligently, website owners can ensure their site remains healthy, accessible, and visible in the ever-evolving digital landscape.
Redirects are fundamental components of website management, acting as signposts on the digital highway. They guide both users and search engine crawlers from one URL to another, ensuring traffic reaches the intended destination even when the original path has changed. Far from being mere technical footnotes, redirects are strategic tools vital for maintaining a healthy online presence.
Their importance stems from a dual role. Firstly, they are critical for user experience. When a user clicks a link or bookmark expecting certain content, encountering a "404 Not Found" error is frustrating and often leads them to abandon the site. Well-implemented redirects ensure seamless navigation, automatically forwarding users from old or non-existent URLs to relevant, live pages, thus preserving user satisfaction and trust.
Secondly, redirects are indispensable for search engine optimisation (SEO). Search engines invest significant effort in crawling and indexing the web; redirects inform them when content has moved permanently or temporarily. Proper redirection helps preserve the hard-earned ranking signals, often referred to as "link equity" or "PageRank," associated with the original URL, transferring much of this value to the new destination. This prevents catastrophic drops in search visibility when URLs inevitably change due to site restructuring, content updates, or migrations. Furthermore, efficient redirect management helps search engines crawl a site more effectively, preventing wasted resources on dead ends.
Ignoring or mismanaging redirects can have severe consequences. Broken links lead to poor user experiences, increased bounce rates, and potentially lost conversions. From an SEO perspective, failing to redirect properly can result in the loss of valuable link equity, fractured ranking signals, wasted crawl budget as search engines repeatedly hit non-existent pages, and ultimately, diminished organic traffic and damaged site credibility.
Understanding how redirects function and how to implement them correctly is therefore not optional, but essential for anyone managing a website. This guide provides a comprehensive overview of different redirect types, their specific impacts on SEO, common pitfalls to avoid, and best practices for implementation and monitoring, ensuring your website navigates changes effectively while safeguarding its search performance. The communication between a website owner, its users, and search engines relies heavily on these signals; miscommunication, such as using the wrong redirect type or creating confusing pathways like loops, directly translates to negative outcomes for both user experience and SEO effectiveness. The need for meticulous redirect management grows significantly with website size and complexity; larger sites undergoing frequent updates, migrations, or structural changes face amplified risks from inefficient redirection, making careful planning and execution paramount.
Decoding Redirect Types: Choosing Your Path
At the heart of redirection lies the HTTP status code, specifically those in the 3xx series. These codes are server-side responses that instruct the browser or search engine crawler on how to proceed when the requested URL is not the final destination. Understanding the nuances between the primary redirect types is crucial for effective SEO.
301 Moved Permanently:Often hailed as the "gold standard" for SEO , the 301 status code signals that a URL has permanently moved to a new location. It tells search engines and browsers that the old URL is defunct and should no longer be requested or indexed; the new URL is the definitive replacement. Its primary SEO benefit is its ability to pass the majority of link equity (ranking power) from the old URL to the new one, typically estimated between 90-99%. This makes it essential for scenarios like changing domain names, migrating to HTTPS, rebranding involving URL changes, permanently deleting pages while providing a relevant alternative, or consolidating duplicate content into a single canonical version. It's worth noting that browsers may cache 301 responses aggressively, meaning users might be automatically sent to the new URL on subsequent visits without re-checking the old one.
302 Found / Moved Temporarily:The 302 status code indicates that a resource has been temporarily moved. The key implication is that the original URL is expected to be reinstated at some point. Historically, 302 redirects were not considered reliable for passing link equity, as search engines understood the move was temporary. While Google representatives have stated that they may treat long-standing 302s like 301s if they appear permanent, relying on this is risky from an SEO perspective. Using a 302 for a permanent move can lead to confusion, potentially splitting ranking signals or causing the old URL to remain indexed. Legitimate use cases include A/B testing different page versions, redirecting users during very short-term site maintenance, or handling temporary promotional pages. For permanent changes, 301 is almost always the safer and clearer choice for SEO.
307 Moved Temporarily:Introduced as part of the HTTP 1.1 specification, the 307 redirect is essentially a more specific version of the 302, explicitly designated for temporary moves. Its crucial distinguishing feature is that it mandates the client (browser/bot) to preserve the original HTTP request method (e.g., GET, POST) when making the request to the new URL. This is vital for situations like temporarily redirecting a page that handles form submissions via POST; using a 302 might cause the browser to incorrectly switch to a GET request for the new URL, potentially breaking functionality. For SEO purposes, search engines generally treat 307s like 302s – as temporary signals that do not pass link equity.
308 Permanent Redirect:The 308 status code is the permanent counterpart to the 307. Like the 301, it signals that a resource has permanently moved to a new location. Its key difference from the 301 is that it also mandates the preservation of the original HTTP request method. This makes it the technically correct choice for permanently moving URLs that handle non-GET requests, such as forms processing POST data or API endpoints. Crucially for SEO, the 308 redirect passes link equity just like a 301 , and Google has confirmed they treat 308s essentially the same as 301s in terms of indexing and ranking signal transfer. While sometimes described as technically "cleaner" if request methods are mixed or unknown, for most standard web page moves (which use GET), the 301 remains perfectly sufficient and more widely understood.
The inclusion of 307 and 308 redirects reflects the web's evolution towards more complex interactions beyond simple page fetching, such as those involving APIs and dynamic form submissions. These newer codes provide necessary precision. However, the decision between 301 and 308 (or 302 and 307) primarily rests on the technical requirement of preserving the request method, not on seeking a different SEO outcome regarding permanence or link equity transfer, as Google handles the permanent types (301/308) similarly.
Link Equity and Redirects
One of the most critical functions of redirects, particularly 301 and 308, is the preservation and transfer of "link equity". Also known as PageRank, link juice, or SEO authority, link equity represents the value or ranking power passed from one page to another through hyperlinks. Pages accumulate this equity over time through internal and external links, and it's a significant factor in how search engines rank pages.
Permanent redirects (301 and 308) are specifically designed by HTTP standards and interpreted by search engines as the primary mechanism for transferring the bulk of this accumulated value when a page permanently moves. While the exact percentage transferred has been debated – with figures like 90-99% often cited and Google representatives sometimes suggesting all 30x redirects pass PageRank – the established SEO best practice is unequivocal: use 301 or 308 for permanent moves to reliably consolidate ranking signals and pass authority. The semantic clarity of "permanent" signals to search engines that the old page's value should now be attributed to the new one.
Relying on temporary redirects (302 or 307) for permanent changes introduces unnecessary risk. Because these codes signal a temporary situation, search engines may be hesitant to fully transfer link equity or may continue to index the original URL alongside the temporary one, effectively splitting the ranking signals and diluting the potential of the new page. This can significantly hinder the new page's ability to achieve the ranking position previously held by the original.
Therefore, preserving link equity is a cornerstone reason for meticulously implementing 301/308 redirects during major website changes like domain migrations, rebranding efforts that involve URL changes, switching to HTTPS, or consolidating multiple weaker pages into a single stronger one. It ensures that the authority built over potentially years is not lost but is instead channeled to the new location. While there might be a theoretical small loss of equity even through a single 301/308 hop , this is generally considered minimal compared to the potential losses from using the wrong redirect type or from issues like redirect chains, which demonstrably dilute equity with each step. The practical focus should be on using the correct permanent redirect type (301/308) for permanent moves to maximise the likelihood of proper signal transfer, rather than getting caught up in precise percentage debates.
However, simply using a 301 or 308 does not automatically guarantee perfect SEO value transfer. The implementation must be clean, avoiding issues like chains (discussed next), and critically, the destination page must be relevant to the original. Redirecting a page about "blue widgets" to a completely unrelated page about "red shoes," even with a 301, is unlikely to transfer the topical authority effectively and may confuse both users and search engines. Relevance is key for the redirect to make sense contextually and for the transferred equity to be meaningful.
Redirects and Crawl Budget: Making Every Crawl Count
Search engines like Google don't have infinite resources; they allocate a finite amount of time and resources, known as the "crawl budget," to crawling any given website. This budget determines how many pages can be crawled and how often. For large websites, sites with frequently updated content, or sites undergoing significant changes, optimizing crawl budget is crucial to ensure important pages are discovered, indexed, and updated in a timely manner.
Redirects inherently consume crawl budget because each redirect encountered forces the crawler to make an additional HTTP request to follow the path to the next URL. While a single, necessary redirect is usually not problematic, inefficiencies in redirect implementation can significantly waste this limited budget.
Redirect Chains are a major culprit. When a URL redirects to another URL, which then redirects to a third (or more), each "hop" consumes crawl budget. Googlebot typically follows a limited number of redirects in a chain (often cited as up to five hops) before abandoning the crawl attempt to conserve resources. This means that content located at the end of a long redirect chain may never be reached or indexed by the crawler. Furthermore, chains can delay the indexing of the final destination page and potentially slow down the crawling of other important content on the site if the budget is squandered on unnecessary hops.
Redirect Loops, where a chain inadvertently directs back to an earlier URL (e.g., A -> B -> C -> A), are even more detrimental. They create an infinite trap for crawlers, consuming budget endlessly until the crawler gives up, and making the intended content completely inaccessible.
Soft 404 Errors also waste crawl budget. These occur when a non-existent page incorrectly returns a 200 OK success code instead of a 404 Not Found or 410 Gone code. Google crawls the URL expecting content, receives a success code, but then has to render and analye the page to realiit's actually an error page (or thin content). This extra processing consumes crawl resources unnecessarily, and these pages may continue to be crawled repeatedly.
Client-Side Redirects (Meta Refresh and JavaScript redirects) can also be inefficient from a crawl budget perspective. Unlike server-side 3xx redirects which are signaled immediately in the HTTP header, client-side redirects require the crawler to download, parse, and render the page content to discover the redirect instruction. This rendering process consumes significantly more resources and time compared to simply reading a header, potentially slowing down the overall crawl.
Optimising crawl budget in relation to redirects involves several best practices:
Eliminate Chains and Loops: Always redirect directly from the original URL to the final destination URL. Audit regularly to find and fix chains by updating the initial redirect.
Fix Soft 404s: Ensure non-existent pages return a proper 404 or 410 status code.
Prioritise Server-Side Redirects: Use 3xx redirects whenever technically possible, as they are more efficient for crawlers than client-side methods.
Update Internal Links: Regularly audit internal links and update any that point to redirected URLs to point directly to the final destination. This saves crawlers (and users) the extra hop.
Maintain Clean Sitemaps: Ensure XML sitemaps list only the final, canonical destination URLs, not URLs that are redirected.
These inefficiencies create an "opportunity cost." Every bit of crawl budget wasted on navigating a redirect chain or processing a soft 404 is budget that could have been used to discover new content, index important updates, or crawl high-priority pages. Proactively updating internal links to bypass redirects is a prime example of efficiency; while the redirect might function, forcing the crawler through it repeatedly is wasteful. Fixing the source link directly saves resources and improves efficiency.
Example of a 301 redirect implemented due to a URL change.
Strategic Redirect Implementation: Common Scenarios
Applying the correct redirect strategy is crucial in various common website management situations. Here’s how to approach them:
Website Migrations (Domain Change/Restructuring): This is perhaps the most critical scenario for redirects. When moving a website to a new domain or significantly changing its URL structure, implementing page-to-page 301 or 308 redirects for every old URL to its corresponding new URL is essential. This painstaking process is vital to transfer the accumulated SEO value (link equity) and ensure users arriving via old links or bookmarks land on the correct new page. Careful mapping of old URLs to new ones is required before the migration. Post-migration, internal links within the content must be updated to point to the new URLs, and the XML sitemap should be updated with the new URLs only.
HTTP to HTTPS Migration: Moving a site to secure HTTPS requires site-wide 301 or 308 redirects from every HTTP URL to its identical HTTPS version. This ensures all traffic is forced to the secure version and consolidates ranking signals to the HTTPS URLs. Canonical tags should also be updated to reference the HTTPS versions. Implementing HTTP Strict Transport Security (HSTS) can further enhance security, although it can sometimes lead to browsers performing internal 307 redirects if configured.
Rebranding (with URL changes): Similar to a domain change, if a rebrand involves changing the website's domain name or URL structure, 301 or 308 redirects are necessary to transfer the existing brand authority, link equity, and user trust associated with the old URLs to the new ones. This prevents having to rebuild the site's SEO presence from scratch.
Content Pruning/Deletion: When removing pages:
If the page is truly gone and there is no relevant replacement content anywhere on the site, the URL should return a 404 (Not Found) or 410 (Gone) status code. The 410 code is a slightly stronger signal that the removal is permanent and intentional. This tells search engines to de-index the page.
If there is a relevant replacement page (e.g., an updated version, a similar product, a parent category page), then implement a 301 redirect from the old URL to the most relevant new URL. This preserves user experience and passes link equity.
Avoid indiscriminately redirecting all deleted pages to the homepage. This is poor practice, often results in soft 404 errors as the homepage is rarely relevant, and provides a bad user experience. The redirect target must be the most relevant possible alternative. If no relevant alternative exists, a 404/410 is better than an irrelevant redirect.
Content Consolidation: When merging several similar or overlapping pages into a single, comprehensive "mother" asset, use 301 redirects from each of the old, merged pages to the new canonical URL. This funnels all traffic and link equity from the retired pages into the consolidated piece, strengthening its authority and ranking potential.
URL Structure Changes/Site Restructuring: If reorganising site categories or changing URL paths for existing content, 301 or 308 redirects are needed to map the old URLs to their new locations. This ensures that internal links, external links, and user bookmarks continue to function correctly and pass SEO value.
Handling www vs. non-www and Trailing Slashes: Websites should consistently use one preferred version of their domain (e.g., https://www.example.com or https://example.com) and URL format (e.g., with or without a trailing slash). Implement 301 redirects to enforce the chosen canonical version, redirecting all other variations to it. This prevents duplicate content issues and consolidates link signals.
Across all these scenarios, the underlying goal is to manage change effectively. Redirects act as the bridge, ensuring continuity for users and search engines by clearly signaling where content has moved or why it's no longer available, thereby preserving accumulated value and preventing confusion. The choice of redirect target when dealing with removed content is particularly important; relevance must guide the decision to avoid confusing users and triggering soft 404s.
Client-Side Redirects: When and How (Cautiously)
While server-side 3xx redirects are the standard and preferred method for SEO, there are situations where redirection happens on the client-side – meaning the redirect is triggered within the user's browser after the initial page starts loading, rather than immediately by the server. The two main types are Meta Refresh and JavaScript redirects.
Meta Refresh:This method uses an HTML meta tag within the <head> section: <meta http-equiv="refresh" content="X; URL='new-url.html'">, where X is the delay in seconds before redirecting. These often display messages like "If you are not redirected in X seconds, click here".
SEO Implications: Meta refreshes are generally not recommended for SEO purposes. They are slower than server-side redirects because the browser must first download and parse the HTML to find the tag. They can be confusing for users, potentially disrupt the browser's back button functionality, and may not reliably pass link equity. While Google has indicated it might treat an instant meta refresh (0-second delay) as equivalent to a 301 , server-side redirects remain the strongly preferred and more reliable method for permanent moves.
JavaScript Redirects:These use JavaScript code, such as window.location.href = 'new-url.html', to instruct the browser to load a different URL.
SEO Implications: Similar to meta refreshes, JavaScript redirects are generally not the preferred method for SEO. The critical drawback is that search engines like Google must render the page (execute the JavaScript) to discover the redirect instruction. This rendering process consumes more crawl resources and introduces delays compared to simply reading an HTTP header. If JavaScript execution fails or is blocked, the redirect may be missed entirely. Furthermore, not all search engine crawlers execute JavaScript effectively, meaning the redirect might be invisible to them. Poor implementation can lead to indexing the intermediate page or even soft 404 errors.
When Might Client-Side Redirects Be Used?Despite the drawbacks, there are niche scenarios:
As a last resort when server-side configuration is impossible due to lack of access or platform limitations.
Sometimes used after user interactions like form submissions or logins, where the immediate SEO impact of the redirect itself is less critical.
A specific valid use case exists for Single Page Applications (SPAs). To avoid soft 404 errors when a non-existent route is accessed within a client-rendered SPA, JavaScript can be used to redirect the user to a dedicated error URL (e.g., /not-found) where the server is configured to return a proper 404 status code. In this context, the JS redirect facilitates the correct server response.
Best Practices (If Unavoidable):
For Meta Refresh: If attempting to signal permanence, use a 0-second delay, but strongly consider if a server-side redirect is truly impossible.
For JavaScript Redirects: Place the redirect script as high as possible in the HTML <head> to minimie the delay before execution. Ensure the page triggering the redirect is not indexable itself (e.g., via noindex tag) if it contains no meaningful content. Crucially, ensure the JavaScript is accessible and renderable by Googlebot.
The fundamental issue with client-side redirects for SEO is their reliance on the rendering process. This inherent inefficiency and potential for failure make server-side 3xx redirects the far superior choice whenever control over server configuration is available.
Navigating the Pitfalls: Chains, Loops, and Soft 404s
Even with an understanding of redirect types, implementation errors can severely undermine SEO efforts. Three common pitfalls require particular attention: redirect chains, redirect loops, and soft 404 errors.
Redirect Chains: A redirect chain occurs when a requested URL redirects to a second URL, which then redirects to a third, and potentially more, before reaching the final destination (e.g., URL A -> URL B -> URL C).
Impact: Chains are detrimental for several reasons. They significantly waste crawl budget, as search engine bots must make multiple requests to follow the path. Googlebot may abandon the chain after a certain number of hops (usually around 5), meaning the final destination might not be crawled or indexed. Each hop can also potentially dilute link equity being passed, weakening the final page's authority. Finally, they increase page load time for users, creating a poor experience.
Causes: Chains often arise accidentally during website migrations or sequential content updates where previous redirects are not audited and updated to point to the latest final destination. This lack of proper change management leads to layered, inefficient redirect paths.
Fix: Identify chains using website crawlers (like Screaming Frog, Oncrawl), browser developer tools, or server log analysis. The solution is to update the very first redirect in the chain to point directly to the final destination URL, eliminating all intermediate steps.
Example of a short redirect chain --> there's more then 1 redirect until the final destination is reached.
Redirect Loops:A redirect loop is a specific type of chain where the sequence eventually redirects back to a URL earlier in the chain, creating an infinite cycle (e.g., URL A -> URL B -> URL A).
Impact: Loops make the content completely inaccessible to both users (who will see a browser error like "ERR_TOO_MANY_REDIRECTS") and search engine crawlers (which get trapped and eventually abandon the attempt). They are a severe waste of crawl budget and prevent the involved pages from being indexed.
Fix: Identify loops using website crawler tools. Analyze the loop to pinpoint the incorrect redirect step. Break the loop by correcting the faulty redirect to point to the intended final destination or by removing the redirect entirely if it's no longer needed.
Soft 404 Errors:A soft 404 occurs when a URL for a page that doesn't actually exist (or has very thin, unhelpful content) returns a 200 OK (Success) HTTP status code instead of the appropriate 404 (Not Found) or 410 (Gone) code.
Common Causes: Serving a custom "Page Not Found" design but failing to send the 404 header; redirecting all non-existent URLs to the homepage; having empty product category pages or internal search result pages that return 200 OK; pages with extremely thin or boilerplate content that Google deems unhelpful.
Impact: Soft 404s confuse search engines, making it harder for them to understand the site's structure. They waste crawl budget as Google crawls these URLs expecting valid content, only to find an error or useless page served with the wrong status code. This can ultimately lead to these URLs (and potentially others, if budget is wasted) not being properly indexed or being removed from the index.
Fix: The fix depends on the nature of the URL:
If the page truly should not exist: Configure the server to return a proper 404 or 410 status code directly for that URL. A custom, helpful 404 page can still be displayed to the user, but it must be served with the 404 HTTP header. Do not redirect 404s to the homepage. This practice ignores the principle of relevance; the homepage is rarely a suitable substitute for the specific content the user or bot sought, leading to confusion and the soft 404 signal.
If the page content has moved: Implement a 301 or 308 redirect to the new, relevant URL.
If the page exists but has thin content: Significantly improve the content to provide genuine value.
If the page exists but should not be indexed (e.g., empty search results): Use a noindex meta tag on the page or potentially block via robots.txt if appropriate (though noindex allows crawling while preventing indexing, which can be preferable).
How to Spot Redirect Issues
Want to make sure your redirects are working properly? Check here:
Google Search Console → Look for 404s and redirected URLs.
Google Analytics → Find error pages that still get traffic.
SEO tools (like Screaming Frog) → Identify redirect chains, missing redirects, or bad targets.
Auditing and Monitoring: Keeping Your Redirects Healthy
Redirect management is not a "set it and forget it" task. Websites evolve, content changes, and platforms get updated, all of which can introduce redirect errors or render existing redirects obsolete or inefficient. Therefore, regular auditing and ongoing monitoring are essential to maintain a healthy redirect structure.
Tools for Identification:A combination of tools provides the most comprehensive view:
Google Search Console (GSC): This free tool from Google is indispensable. The Index Coverage report highlights pages with redirect errors, confirms which redirected pages Google has processed ("Page with redirect" status), and flags soft 404 errors. The URL Inspection Tool allows checking the status and redirect path of individual URLs as Google sees them.
Website Crawlers: Desktop software (like Screaming Frog SEO Spider, Sitebulb) or cloud platforms (like Oncrawl, Deepcrawl) are crucial for proactively identifying issues across the entire site. Configure them to follow redirects and report on status codes, redirect chains, loops, and target URLs.
Browser Developer Tools: The "Network" tab in Chrome DevTools or similar browser tools allows manual inspection of the HTTP headers and redirect sequence for any single URL visited.
Server Log Analysis: Analysing server access logs can reveal how search engine bots (and users) are actually interacting with redirects, identifying frequently hit redirected URLs, crawl traps, or unexpected status codes.
Regular Audit Process:Implementing a routine audit process helps catch issues early:
Schedule Periodic Crawls: Depending on site size and the frequency of changes, run full site crawls specifically configured to detect redirect issues (chains, loops, incorrect types like 302s for permanent moves, redirects leading to 404s) on a regular basis (e.g., monthly, quarterly).
Monitor GSC: Check the Coverage report in GSC frequently (e.g., weekly) for any newly reported errors or warnings related to redirects or indexing.
Check Internal Links: During audits, identify internal links that point to URLs which then redirect. Update these source links to point directly to the final destination URL to improve efficiency.
Post-Change Verification: Always perform a thorough redirect check immediately after major website changes, such as migrations, platform updates, redesigns, or significant content restructuring.
Sitemap Hygiene: Regularly verify that your XML sitemap(s) contain only live, final destination URLs (status code 200) and do not include any URLs that redirect.
Proactive monitoring allows for the early detection and correction of redirect problems before they escalate and cause significant harm to crawl budget allocation, link equity flow, or user experience. Waiting for ranking drops or user complaints is a reactive approach that indicates damage has already occurred. Combining insights from different tools offers a more robust picture: GSC shows Google's view, crawlers simulate discovery site-wide, and logs reveal actual bot behavior, enabling better prioritization of fixes.
Conclusion: Mastering Redirects for a Healthier Site
Redirects are far more than a technical necessity; they are a critical element of effective technical SEO and website management. Properly implemented, they ensure seamless user journeys, preserve hard-won search engine rankings, and allow websites to evolve without losing valuable authority or confusing search crawlers.
The key takeaways are clear:
Choose the Right Signal: Understand the difference between permanent (301, 308) and temporary (302, 307) redirects and use the appropriate code for the situation. Consider whether the request method needs preservation (using 307/308) for non-standard requests.
Prioritize Server-Side: Whenever possible, use server-side 3xx redirects, as they are more efficient and reliable for SEO than client-side methods like Meta Refresh or JavaScript redirects.
Preserve Link Equity: Leverage 301 and 308 redirects for permanent moves to transfer the maximum possible ranking power to new URLs.
Maintain Cleanliness and Relevance: Avoid redirect chains and loops at all costs, as they waste crawl budget and harm user experience. Ensure redirect targets are relevant to the original URL, and fix soft 404 errors by serving correct status codes (404/410 for gone pages, 200 for valid pages, 301/308 for moved pages).
Audit Continuously: Redirect management is an ongoing process. Regularly use tools like Google Search Console and website crawlers to monitor for errors and inefficiencies.
Ultimately, effective redirect management is about managing change and maintaining clarity. As websites grow and adapt, redirects serve as the essential communication tool that ensures these changes don't result in broken pathways, lost SEO value, or confusion for users and search engines. Mastering redirects is mastering a fundamental aspect of technical SEO, providing the stable foundation upon which other efforts like content creation, link building, and user experience optimiion can thrive. By implementing redirects thoughtfully and monitoring them diligently, website owners can ensure their site remains healthy, accessible, and visible in the ever-evolving digital landscape.
Latest posts
Knowledge Base
Interviews, tips, guides, news and best practices on the topics of search engine optimisation, SEA and digital strategy.
From audits no one implements to tool overkill and perfectionism in the wrong places: The 7 most common budget killers in SEO projects – and how to protect your budget.
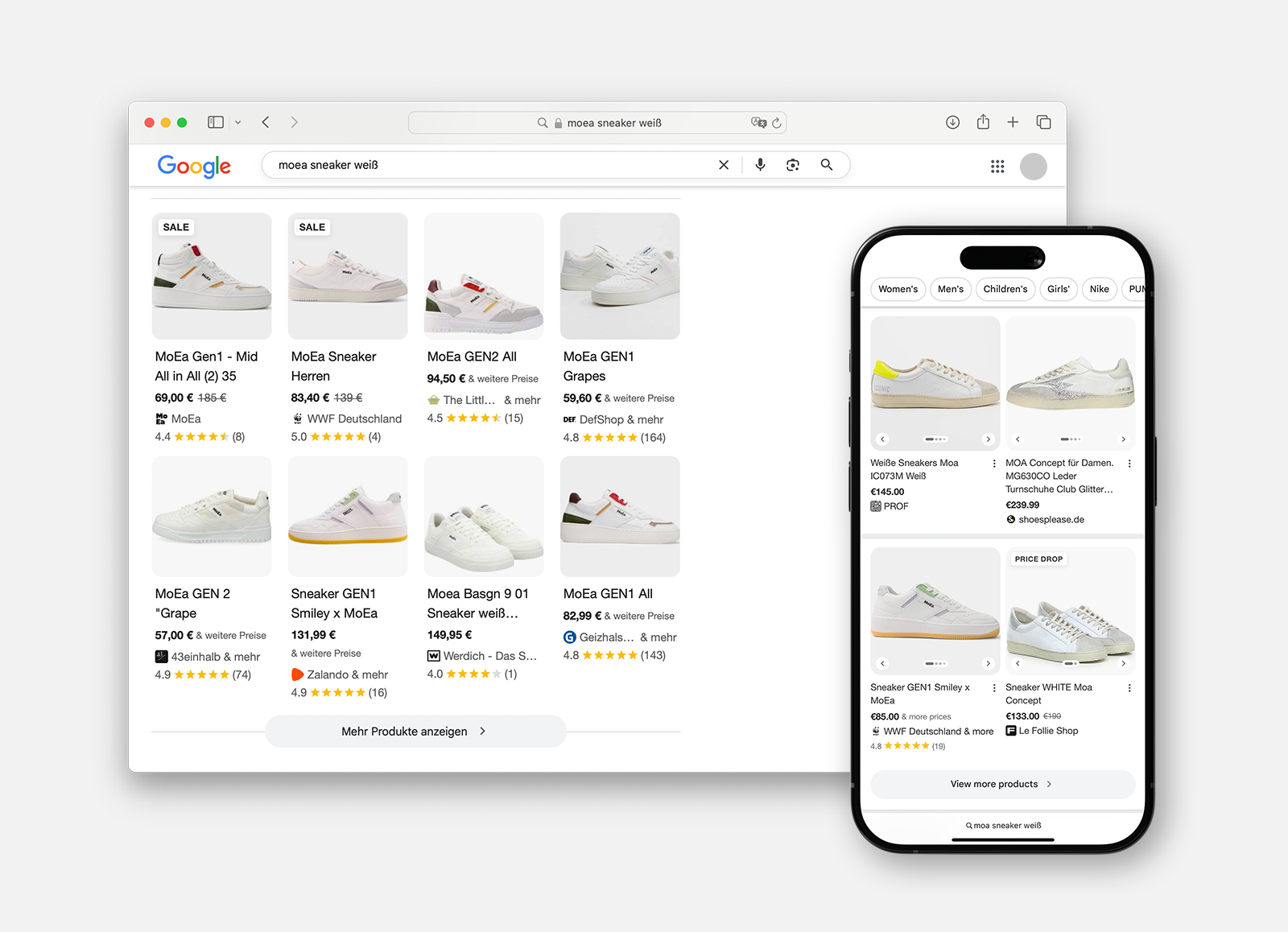
With Free Listings, Google offers free placement for products in search results. Investing early in data quality and presentation ensures visibility and qualified traffic – and thus a real competitive advantage.
Search results are changing with AI-powered results. Boost visibility by prioritising structured data, strengthening brand authority, optimising your Google Merchant Center, and securing Google's Top Quality Score Badge.